
点击“子弥实验室” 关注我们



大家好,我是子弥。
在“元经济学”中我们讨论了元宇宙的一种“开发者/创作者经济体”,今天讨论下为之服务的内容构建工具。我们想用电子手段和感官刺激让人们感觉到自己置身于一个虚拟的立体视觉中,而且要与真实世界的体验类似,甚至一致,那么就绕不开一个话题,如何骗过我们的眼睛。
程序化建模procedural model就是一种重要工具,之前多用于电影和大型游戏,如今已经成为元宇宙主流的解决方案。虚拟世界的趋势要求持续有效的创建和更新虚拟环境。这就要求做到“即时建筑”,比如大楼更换的玻璃窗、站点调整广告牌、风吹倒的树,能“即时”反应到孪生的虚拟城市之中。
我们也会讨论两种不同的类型:重建和生成。介绍一些工具和技术,最后探讨一下未来趋势。

内容是平面互联网的核心,也是元宇宙的核心
欺骗眼睛
整个内容创造史,就是人自主发起的,对人的眼睛和大脑的欺骗史。每一次技术革新,都在让欺骗艺术更为登峰造极。比如利用双眼形成立体视场的原理对构图进行透视设计,比如利用视觉暂留现象发明了电影、动画片这些运动的图像。

飞翔的鸟的错觉,是电影和动画的雏形
除了电影本身的技术原理来自于对眼睛的欺骗外,电影技巧处处充满“欺骗”,比如利用视觉角度的差异欺骗眼睛
电影拍摄中,拍摄的实际场景和呈现给观众的,其实是不完全一样的。

《最后安全》中劳埃德吊钟楼

实际的拍摄场景

卓别林倒着轮滑差点摔到楼下,观众一片惊呼

真实的拍摄场景是这样的
库里肖夫效应是一种关于蒙太奇的理论。库里肖夫设计了一个实验,他要求当时著名演员莫兹尤辛保持面无表情的状态,然后拍摄了一段镜头。
随后库里肖夫将这段镜头插入到不同的段落中,与三个表现不同主题的镜头相连接。
第一组镜头是:面无表情的镜头+一盘稀汤
第二组镜头是:面无表情的镜头+一口棺材和一个死去的女孩
第三组镜头是:面无表情的镜头+一个优雅的女子
每个段落中用的是同一个莫兹尤辛的脸部特写,一旦配合了前后镜头,在观众的意识中,会产生完全不同的感受,他们会觉得那是些不同的镜头,每个镜头展现的是完全不同的表情。
所有看过视频的观众都认为莫兹尤辛演技爆棚。看到稀汤的人认为演员将灾荒的饥饿神情演绎的淋漓尽致;看到棺材的人认为演员演活了悲伤至极;而看到优雅女子的人,感觉演员的表情像是注视着情侣,内心充满了喜悦和欣慰。
库里肖夫

莫兹尤辛面无表情的镜头

稀汤

棺材中的小女孩

一个优雅的女人
在电影图像流中,“刚刚过去的时刻”被保留在流逝的“此刻”之中,从而使得此刻呈现之物具有了内容:电影所体现的显然正是这一点。在之后的镜头中,此刻的这一镜头将变成持留之物而呈现故事。而且,从位于它之前的被持留之物开始,它由于包含并维持着即将到来的此刻,它是一种前摄。这就是斯蒂格勒三种持留的融合,也是“持留的剪辑和联系”的条件。
通俗点说,就是电影的时间流逝不同于生活的时间流逝,生活的时间如溪流不可斩断,但电影可以通过镜头的拼接和组合来契合人类复杂的心理,在一段视频中,某一镜头必须与之前之后所有的镜头相联系,否则便无法形成故事。正是这种有趣的灵活性和不确定性为电影艺术家撑起了创作空间。
将图像和视频数字化,也是对眼睛的欺骗。二十年前,人们看的电视都是模拟信号。图像的亮度与色彩变化和真实的变化是严格吻合的。摄像机将真实的图像模拟出来转成电信号,故称为模拟信号。模拟信号最大的问题在于抗干扰性弱,如果电信号强度变弱,那么最后生成的图像就有可能会变暗或者颜色发成偏移。
关键是,空间中充满了各种无线电波,都会形成干扰,这些捣乱的调皮鬼会以“雪花”和干扰条纹的形式在屏幕上出现。甚至宇宙微波背景辐射都会影响到信号的精确传输(宇宙微波背景辐射就是通过对信号的干扰进行分析发现的)。

模拟信号的传输抗干扰性较差
有聪明人想到:为什么非要精确的模拟图像呢?我们又不是第一次骗眼睛了,再骗一次吧。
数字化是将本来连续的模拟图像分割成一小小色块,采样量化。就像拼乐高一样拼出来一幅图画。我们可以为不同的颜色和亮度编码,这样发送出去的就不是一个波形,而是一堆0和1,是一堆高低电平脉冲,自然抗干扰性倍增。
只要色块做到足够小,眼睛无法分辨那么小的离散点,看起来还是跟原图相似。分辨率越高,就意味着数字图像包含的内容越丰富。而当分辨率超过4K时,一副数字的图像(点阵)所包含的信息已经超过眼睛从模拟图像中采样所提取的信息了。当然,这时候是否算是欺骗就不确定了。
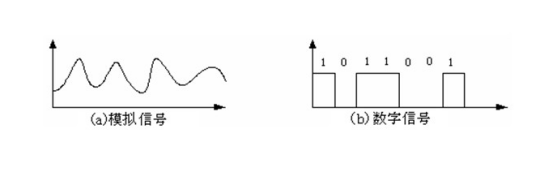
模拟信号和数字信号的区别
数字信号利用足够小的色块拼出图像进行传输
三维的图像一般使用点云。通过摄像机进行深度的扫描之后,在二维的点阵之上增加一个维度的数据,成为点云。一般通过结构光、ToF、双目视觉等获得深度信息。

刺客信条还原三维的巴黎圣母院
然而纯粹三维点云还是不够的,更进一步,需要增加光场信息,一共增加到7个维度。
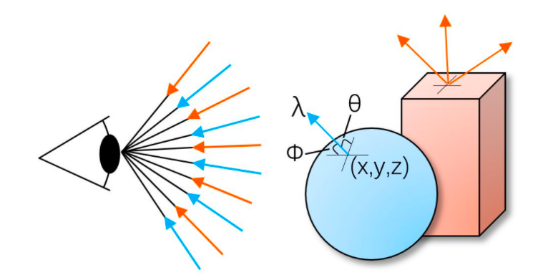
光场Light Field在1936年被提出,MIT的Parry Moon和Gregory Timoshenko在1939年翻译为英文。Parry Moon在1981年提出了Photic Field。谷歌发布了Welcome to light field。

谷歌光场视频体验
上图参考视频:
其实对于光线颜色的模拟也是依靠对眼睛的欺骗完成的。人类可以看到七种颜色的光,但如果眼睛中也相应的长七种识别颜色的视锥细胞,那么人的眼球恐怕要长到橙子般大小。
人眼只用了红绿蓝三种视锥细胞来模拟不同的颜色。如果只有一个视锥细胞活跃,大脑会按照红、绿、蓝中的某一种颜色渲染图像,如果有两个视锥细胞活跃,大脑会按照青色、黄色或者是偏粉的洋红色来渲染图像;如果三个视锥细胞活跃,大脑就会用明亮的白色渲染图像。
所以我们看到的所谓真实的世界,也不过是大脑的渲染而已。
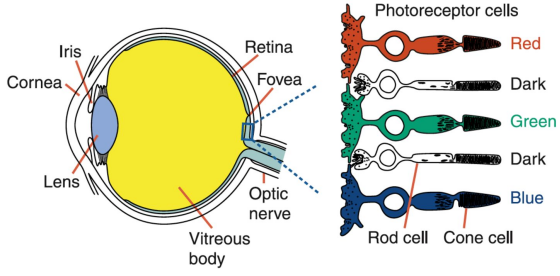
人类眼球视神经分布
早期的烛光、白炽灯光等光源是连续光谱,眼睛可以像适应日光一般适应这些光源。但是,自从人类进入了LED照明时代,每一个光源都是线状光谱,于是人类就又耍起了欺骗自己眼睛的老把戏,用红绿蓝三色光或者蓝黄双色光来欺骗眼睛,让眼睛认为看到的是白光,当下大多数人造白光正是如此而来。倘若只是欺骗也就罢了,但是线状光谱直接对视锥细胞进行刺激,会对视力有所影响。特别是高频率的蓝色LED光,会对儿童的视力有一定的伤害。

自然白光、白炽灯、荧光灯、LED频谱
当下也可以通过各种技术利用LED模拟出更接近自然光的照明环境,相应的也带来了高成本。而教育体系的替代黑板的电子白板所使用的的背光和室内照明其实是堪忧的。最关键的是,儿童期视神经发育的损伤是不可恢复的。这可能是近年来儿童眼疾增加的一个可能原因。
生成与重建
在过去十年中,使用算法自动生成虚拟现实环境,已成为数字内容制作的有效解决方案。最少的建模工作,自动重新创建环境是一个引人入胜的想法,它可以在建筑、视频游戏、电影、以及虚拟世界等不同领域带来多种好处。
利用算法而不是手工,通常被认为是虚拟环境的“生成”。其实也都是欺骗眼睛的手段。

L-System

利用分形生成的火焰
它们的一般目的都是相似的:应用参数化的算法来生成三维的场景,根据用户选择来创建三维模型或纹理,而不是都用手动贴。
这种利用算法自动生成的操作,最难处理的是头发和衣服。
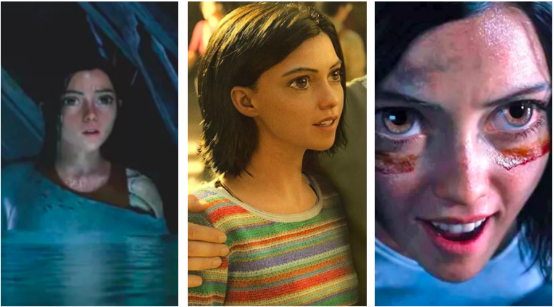
阿丽塔超清晰的眼睛、毛衣纹路、滴水的发梢,皮肤皱褶、唇纹
城市结构的生成也是一个非常有吸引力的目标。基本现在数字孪生的软件都通过成熟的模型拖拽完成(高效的可视化编辑系统)。参数设定,生成房屋和道路,放置物体,然后设置程序化的编程控制方法。比如City Engine。
什么时候采用什么样的技术取决于设计世界的人。无论是计算机图形建模人员还是普通的虚拟世界用户,最有可能的是,即使在考虑程序化方法时,用户也希望手动创建某些特征或进行某些自定义,从而生成混合模型。
毕竟,程序化的目标不是取代人力或个人的创造力,而是提供有效的工具来帮助制作复杂的三维内容,因为那大多数情况下是艰巨而乏味的任务。
引入相似的对象以生产逼真的模型,比如考古学中,创建更高水平的特征至关重要。当真实是主要的关注点时,以现实为基础的重建技术(复制/复原),就会作为最重要的技术被引入。比如激光扫描。
或者使用采集的信息,驱动已经构建好的模型。比如阿丽塔的动作捕捉。

通过面部捕捉赋予模型以表情
三维素材构建,最直接快捷的方式,是将现实的物体和场景扫描并进行虚拟化,形成数字资产。
上期已经介绍了Epic收购的产品MegaScans,可以精确化扫描千米级的山、河、悬崖、海岸,精确到碎石和沙粒。以及Metahuman,可以更精确的构建人体。

Epic的Metahuman构建的虚拟人
Epic数字人类技术副总裁Vladimir Mastilovic解释说,任何拥有iPhone并且对虚幻引擎有基本了解的人都应该能够使用元人类编辑器,这为互联网上的普通内容创作者打开了大门。
苹果手机的物体捕捉技术能通过手机扫描捕捉高保真的虚拟对象。

苹果的物体捕捉功能
上图视频参考地址如下:
捕捉物品需要多角度的拍摄,根据拍摄位置和拍摄视频合成最终的物品。小型的商品等可以固定摄像头(滑轨)加上可旋转的托盘完成。在网上完成试穿,试戴眼镜,提前试看发型。
通过动作捕捉,就可以自动驱动扫描完成的模型。

虚拟引擎UE4联合苹果手机推出的面部识别
上图视频参考地址如下:
Volograms在7月发布了动作捕捉软件Volu。

动作捕捉软件Volu
除了电影本身的技术原理来自于对眼睛大脑的欺骗外,电影技巧处处充满欺骗,比如利用视觉角度的差异欺骗眼睛
电影拍摄中,拍摄的实际场景和呈现给观众的,其实是不完全一样的。
不久的未来,你去迪士尼的主题乐园时,或许可以和家中的朋友共同进入探险,与他们合作打败灭霸或者收集无限宝石。而他们随时都能听到你的声音,看到你的动作和表情。
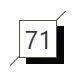
编辑工具
随着科技的发展,编辑工具有时候与采集工具并不区分。例如三维重建之后,智能提取其中元素进行编辑。
MetaHumans可以创建接近真实的物品
或者自动化重建并更新到已有模型中。
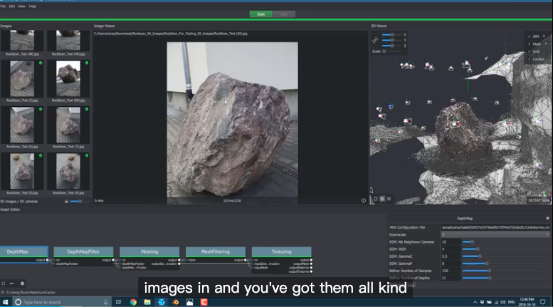
Adobe发布了Adobe Aero,并不区分是重建的还是生成的,都可以导入来编辑AR的场景和内容。
Adode Aero

科技构建新内容形态
科技发展构建新的内容形态,例如游戏、MILES真人秀、旅游等。
在虚拟世界搞房地产,靠谱吗?
一副VR眼镜在任何位置,都可以进入一个梦想到达的地方,比如西藏。
西藏只有布达拉宫吗?西藏是文化圣地,有无数的寺庙和文化遗迹可以去参观。
但面对广袤的土地和高寒的气候,显然游览每一座寺庙并不现实,
好吧,让我们利用传统的图书和图文的形式游览一下,你会是什么感受呢?
















元宇宙需要庞大的基础设施支撑
是不是感觉非常的不给力,不过瘾?
当下的VR文旅可以生成景观的三维全景图,通过VR眼镜就可以做到身临其境。
虽然依旧耍着欺骗眼睛的把戏,但心到也就身到了,也许这个世界本身就是模拟的。

VR文旅将是元宇宙的重要组成部分
愿今后足不出户,便可以畅游西藏,
畅游丝绸之路,
甚至是星辰大海……
(未完待续)

子弥实验室是广东粤港澳大湾区国家纳米科技创新研究院的下属一级单位。由中科院院长白春礼于2020年11月21日在黄埔揭牌成立,中科院院士赵宇亮任实验室主任。
“子弥”一词来源于传统佛教宇宙哲学——“芥子须弥”,意思是微小的芥子中能容纳巨大的须弥山。子弥实验室“小”中“生”大“,思考、设计、产生人类没有的技术和产品,成为改变人类思维模式、改变人类科技进程、改变人类工作模式、改变人类生活方式的发源地。
子弥实验室致力于研究面向未来的关键共性技术,希望寻找对科技充满痴迷,思想未被格式化的人、行为未被同步化的人、认知未被标准化的人、情怀未被世俗化的人,共同用思想创造人类没有的技术和产品。

email:tony@cannano.cn
中国艺术经济网 版权所有。发布者:艺旌经,如若转载,请注明出处:https://www.yiloo.cn/11121.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫